Understanding KV Cache Optimization for LLM Inference
📄 Paper Walkthrough
KV Cache Optimization Strategies for Scalable and Efficient LLM Inference Yichun Xu, Navjot K. Khaira, Tejinder Singh (Dell Technologies) arXiv:2603.20397 · March 24, 2026 · 24 pages · 78 references
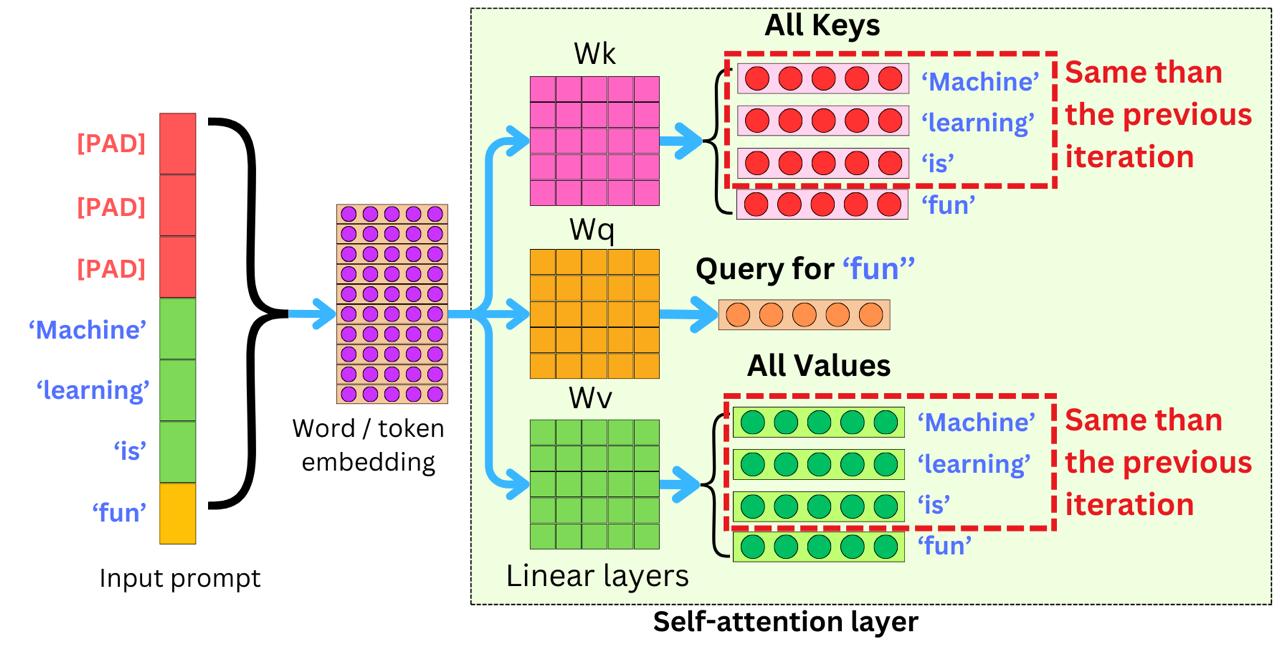
Why KV cache is a problem
- During autoregressive generation, every new token must “see” the K/V vectors of all prior tokens.
- Without caching, every step recomputes everything from scratch → O(N²).
- With caching, KV memory grows linearly with context length:
KV size = 2·H·D·L·B·N. - As context windows stretch from 2K to 100K, 1M, 10M, KV cache consumes all GPU memory, making inference slow, expensive, and impractical.

Five technique categories
| # | Category | One-line idea | Representative work | Typical gain |
|---|---|---|---|---|
| 1 | Cache Eviction | Drop unimportant tokens during generation | H₂O, SnapKV, Ada-KV | ~80% memory cut, near-lossless |
| 2 | Cache Compression | Quantize KV to 2–4 bit or low-rank projection | KIVI, KVQuant, Palu | ×4–×8 memory, lossless or <2% accuracy drop |
| 3 | Hybrid Memory | Move KV to CPU/SSD; keep only hot entries on GPU | vLLM/PagedAttention, FlexGen, Oneiros | Run huge models on one GPU, ×6 batch, ×3–×33 throughput |
| 4 | New Attention | Replace softmax attention: O(N²) → O(N log N) | Linear, Log-Linear, Kimi Linear | ×6.3 throughput, 75% memory cut (Kimi) |
| 5 | Combination | Mix the above four | RocketKV, KVzip, ShadowKV, TailorKV | Best overall; no single technique wins everywhere |
Seven deployment scenarios × recommended methods
| Scenario | Recommended | Why |
|---|---|---|
| Ultra-long context (>1M) single request | Eviction + Compression; Kimi Linear | Memory is the bottleneck; must shrink the cache |
| Minimal model modification | Ada-KV, SnapKV, KIVI | All fine-tuning-free, plug-and-play |
| High-throughput datacenter | PagedAttention/vLLM, Oneiros, ShadowKV | Large batches, lossless, multi-tenant |
| Edge / memory-limited devices | InfiniPot, TailorKV | 8B/128K on a 24GB GPU |
| Multi-turn conversations | RocketKV-MT, KVzip, ShadowKV | Cannot permanently drop tokens like H₂O |
| Prefill-heavy (long prompts) | NACL, HashEvict, LayerKV, MiniCache | Focus on TTFT (time to first token) |
| Accuracy-critical reasoning | PagedAttention | Lossless offload; avoid eviction/compression/linear attention |
Key conclusion
There is no silver bullet.
- Ultra-long context (>1M) → eviction + compression dominate.
- High-throughput serving → hybrid memory dominates (vLLM is still the de facto standard).
- Bandwidth-bound → standalone compression wins.
- New attention mechanisms → the future, but require retraining.
- Future direction: adaptive, multi-stage pipelines that combine techniques dynamically based on context length, load, and hardware.